缓存与分布式锁
1 缓存使用
为了系统性能的提升,我们一般都会将部分数据放入缓存中,加速访问。而 db 承担数据落盘工作
哪些数据适合放入缓存?
即时性、数据一致性要求不高的
访问量大且更新频率不高的数据(读多,写少)
举例:电商类应用,商品分类,商品列表等适合缓存并加一个失效时间(根据数据更新频率 来定),后台如果发布一个商品,买家需要 5 分钟才能看到新的商品一般还是可以接受的。不需要强一致性,需要最终一致性
流程图:

注意:在开发中,凡是放入缓存中的
数据我们都应该指定过期时间,使其可以在系统即使没有主动更新数据也能自动触发数据加载进缓存的流程。避免业务崩溃导致的数据永久不一致问题。
2. 高并发下缓存失效问题
(1) 缓存穿透
缓存穿透最直白的意思就是,我们的业务系统在接收到请求时在缓存中并没有查到数据,从而穿透到了后端数据库里面查数据的过程。
或是指外来大量访问去查询缓存中不存在的值,最终导致需要不断的去查数据库,使数据库压力变大,最终导致程序异常。
缓存穿透是指查询一个一定不存在的数据,由于缓存是不命中,将去查询数据库,但是数据库也无此记录,我们没有将这次查询的 null 写入缓存,这将导致这个不存在的数据每次 请求都要到存储层去查询,失去了缓存的意义。
在流量大时,可能 DB 就挂掉了,要是有人利用不存在的 key 频繁攻击我们的应用,这就是漏洞。
解决:
缓存空结果、并且设置短的过期时间。
(2) 缓存雪崩
简要来讲是指缓存中的key大面积失效,同时有大量的请求过来获取数据,去查看缓存,但是缓存中的数据已经失效,就回去访问数据库,最终导致数据库压力变大。
缓存雪崩是指在我们设置缓存时采用了相同的过期时间,导致缓存在某一时刻同时失 效,请求全部转发到 DB,DB 瞬时压力过重雪崩。
解决:
原有的失效时间基础上增加一个随机值,比如 1-5 分钟随机,这样每一个缓存的过期时间的 重复率就会降低,就很难引发集体失效的事件
(3) 缓存击穿
缓存击穿是指缓存中没有但数据库中有的数据,当一个key非常热点(类似于爆款),在不停的扛着大并发,大并发集中对这一个点进行访问;当这个key在失效的瞬间,持续的大并发就穿破缓存,直接请求数据库,就像在一个屏障上凿开了一个洞。
对于一些设置了过期时间的 key,如果这些 key 可能会在某些时间点被超高并发地访问, 是一种非常“热点”的数据。
这个时候,需要考虑一个问题:如果这个 key 在大量请求同时进来前正好失效,那么所 有对这个 key 的数据查询都落到 db,我们称为缓存击穿
解决:
加互斥锁
① 使用本地锁(sychronized)单体应用
当大量请求全都访问这个数据时,发现缓存中没有,就会访问数据库进行查询,将访问数据库操作的方法使用sychronized加锁,那么这些请求就会排队访问。第一个请求执行完同步操作后会释放锁, 在释放锁之前会将查询到的数据存入缓存中,其他请求进入同步操作会先判断缓存中是否有相应的数据,就避免了多次查库的问题。
//TODO 产生对外内存溢出: OutOfDirectMemoryError
@Override
public Map<String, List<Catelog2Vo>> getCatalogJson() {
//先判断Redis中是否有数据
String catalogJSON = redisTemplate.opsForValue().get("catalogJSON");
if (StringUtils.isEmpty(catalogJSON)) {
// 缓存中没有,向数据库中获取数据
//调用下面的方法
Map<String, List<Catelog2Vo>> catalogJsonFromDb = getCatalogJsonFromDb();
return catalogJsonFromDb;
}
//redis中有对应的数据时的逻辑
// 需要从redis中获取数据,并将json数据转换为对象,然后再返回
Map<String, List<Catelog2Vo>> result = JSON.parseObject(catalogJSON, new TypeReference<Map<String, List<Catelog2Vo>>>() {
});
return result;
}
//从数据库查询并封装数据
public Map<String, List<Catelog2Vo>> getCatalogJsonFromDb() {
synchronized (this) {
//将数据库的查询变为一次
List<CategoryEntity> selectList = baseMapper.selectList(null);
// 查出所有一级分类
List<CategoryEntity> level1Categorys = getParent_cid(selectList, 0L);
// 封装数据
Map<String, List<Catelog2Vo>> parent_cid = level1Categorys.stream().collect(Collectors.toMap(k -> k.getCatId().toString(), v -> {
.................封装数据操作..................
}));
// 获取到数据后,要想redis缓存中存放获取到的数据
// 因为redis中key和value都是字符串,所有要想向redis中存放数据就要先将数据对象转化成为Json的格式,之后在保存到Redis中
String value = JSON.toJSONString(parent_cid);
redisTemplate.opsForValue().set("catalogJSON", value);
return parent_cid;
}
}但是使用本地锁的方式在分布式的情景下就会出现问题:每一个服务都是锁住了当前进程,无法锁住其他进程。

3 分布式锁
初级
原理是使用redis中的setnx命令,根据官方文档 :
Redis Setnx( SET if Not eXists )命令在指定的 key 不存在时,为 key 设置指定的值,这种情况下等同 SET 命令。当 key存在时,什么也不做。
返回值
整数:
1 如果key被设置了
0 如果key没有被设置
而在Java中对应方法是:
public Boolean setIfAbsent(K key, V value) { byte[] rawKey = this.rawKey(key); byte[] rawValue = this.rawValue(value); return (Boolean)this.execute((connection) -> { return connection.setNX(rawKey, rawValue); }, true); } // 此方法可以设置key的过期时间以及时间类型 public Boolean setIfAbsent(K key, V value, long timeout, TimeUnit unit) { byte[] rawKey = this.rawKey(key); byte[] rawValue = this.rawValue(value); Expiration expiration = Expiration.from(timeout, unit); return (Boolean)this.execute((connection) -> { return connection.set(rawKey, rawValue, expiration, SetOption.ifAbsent()); }, true); }高级
读锁和写锁
为了保证一定能读取到数据,修改期间,写锁是一个
排它锁(互斥锁、独享锁),而读锁是一个共享锁。写锁没有释放就必须等待

总结:只要有写的存在,都需要等待。
缓存数据一致性
保证一致性模式
双写模式
先将数据写入数据库,然后再修改缓存。

失效模式
只要更新数据库数据,在更新完成后就删除缓存中的数据,使缓存失效。
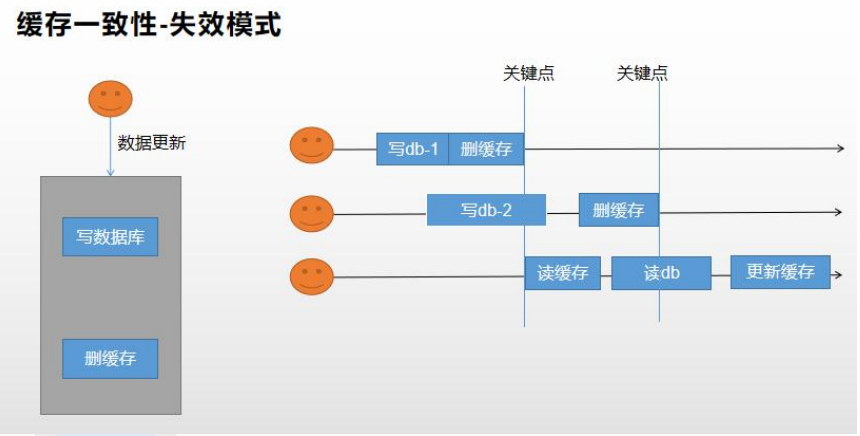
但是两种都会产出数据不一致的问题。
改进方法
1)分布式读写锁
分布式读写锁。读数据等待写数据整个操作完成
(2)使用alibaba的cananl
cananl会记录数据库的更新,会将变动的信息记录到cananl中,然后对redis进行更新。

