什么是 Redis?
Redis 是一种基于内存的数据库,对数据的读写操作都是在内存中完成,因此读写速度非常快,常用于缓存,消息队列、分布式锁等场景。
为什么用 Redis 作为 MySQL 的缓存?
主要是因为 Redis 具备「高性能」和「高并发」两种特性。
Redis 具备高性能
假如用户第一次访问 MySQL 中的某些数据。这个过程会比较慢,因为是从硬盘上读取的。将该用户访问的数据缓存在 Redis 中,这样下一次再访问这些数据的时候就可以直接从缓存中获取了,操作 Redis 缓存就是直接操作内存,所以速度相当快。
Redis 具备高并发
单台设备的 Redis 的 QPS(Query Per Second,每秒钟处理完请求的次数) 是 MySQL 的 10 倍,Redis 单机的 QPS 能轻松破 10w,而 MySQL 单机的 QPS 很难破 1w。
所以,直接访问 Redis 能够承受的请求是远远大于直接访问 MySQL 的,所以我们可以考虑把数据库中的部分数据转移到缓存中去,这样用户的一部分请求会直接到缓存这里而不用经过数据库。
Redis 数据类型以及使用场景分别是什么?
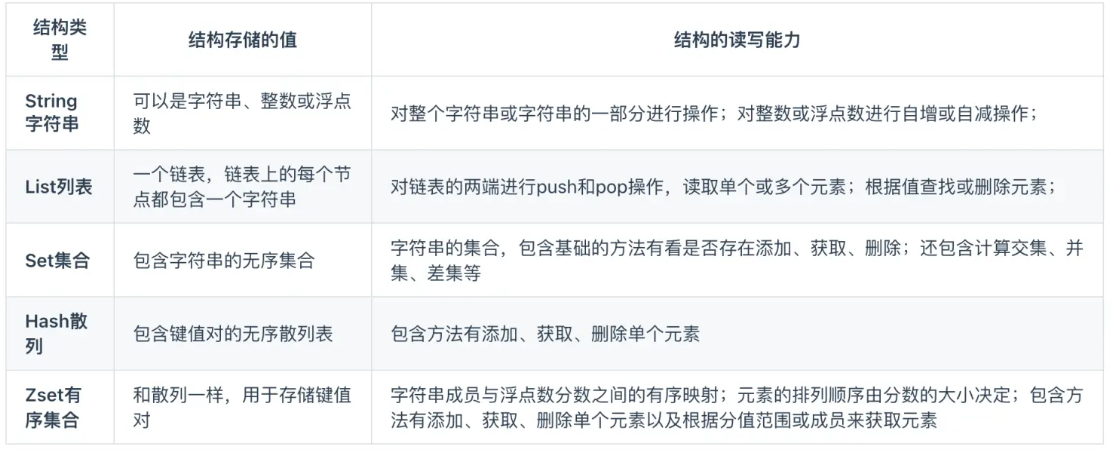
Redis 提供了丰富的数据类型,常见的有五种数据类型:String(字符串),Hash(哈希),List(列表),Set(集合)、Zset(有序集合)。
Redis 是单线程吗?
Redis 单线程指的是「接收客户端请求->解析请求 ->进行数据读写等操作->发送数据给客户端」这个过程是由一个线程(主线程)来完成的。
但是,Redis 程序并不是单线程的,Redis 在启动的时候,是会启动后台线程(BIO)。
Redis 采用单线程为什么还这么快?
- Redis 的大部分操作都在内存中完成,并且采用了高效的数据结构,因此 Redis 瓶颈可能是机器的内存或者网络带宽,而并非 CPU,既然 CPU 不是瓶颈,那么自然就采用单线程的解决方案了;
- Redis 采用单线程模型可以避免了多线程之间的竞争,省去了多线程切换带来的时间和性能上的开销,而且也不会导致死锁问题。
- Redis 采用了 I/O 多路复用机制处理大量的客户端 Socket 请求,IO 多路复用机制是指一个线程处理多个 IO 流,就是我们经常听到的 select/epoll 机制。简单来说,在 Redis 只运行单线程的情况下,该机制允许内核中,同时存在多个监听 Socket 和已连接 Socket。内核会一直监听这些 Socket 上的连接请求或数据请求。一旦有请求到达,就会交给 Redis 线程处理,这就实现了一个 Redis 线程处理多个 IO 流的效果。
Redis 如何实现数据不丢失?
Redis 共有三种数据持久化的方式:
- AOF 日志:每执行一条写操作命令,就把该命令以追加的方式写入到一个文件里;
- RDB 快照:将某一时刻的内存数据,以二进制的方式写入磁盘;
- 混合持久化方式:Redis 4.0 新增的方式,集成了 AOF 和 RBD 的优点;
AOF 日志为什么先执行命令,再把数据写入日志呢?
优点:
- 避免额外的检查开销:因为如果先将写操作命令记录到 AOF 日志里,再执行该命令的话,如果当前的命令语法有问题,那么如果不进行命令语法检查,该错误的命令记录到 AOF 日志里后,Redis 在使用日志恢复数据时,就可能会出错。
- 不会阻塞当前写操作命令的执行:因为当写操作命令执行成功后,才会将命令记录到 AOF 日志。
缺点:
- 数据可能会丢失: 执行写操作命令和记录日志是两个过程,那当 Redis 在还没来得及将命令写入到硬盘时,服务器发生宕机了,这个数据就会有丢失的风险。
- 可能阻塞其他操作: 由于写操作命令执行成功后才记录到 AOF 日志,所以不会阻塞当前命令的执行,但因为 AOF 日志也是在主线程中执行,所以当 Redis 把日志文件写入磁盘的时候,还是会阻塞后续的操作无法执行。
AOF 写回策略有几种?
- Always,这个单词的意思是「总是」,所以它的意思是每次写操作命令执行完后,同步将 AOF 日志数据写回硬盘;
- Everysec,这个单词的意思是「每秒」,所以它的意思是每次写操作命令执行完后,先将命令写入到 AOF 文件的内核缓冲区,然后每隔一秒将缓冲区里的内容写回到硬盘;
- No,意味着不由 Redis 控制写回硬盘的时机,转交给操作系统控制写回的时机,也就是每次写操作命令执行完后,先将命令写入到 AOF 文件的内核缓冲区,再由操作系统决定何时将缓冲区内容写回硬盘。

AOF 日志过大,会触发什么机制?
Redis 为了避免 AOF 文件越写越大,提供了 AOF 重写机制,当 AOF 文件的大小超过所设定的阈值后,Redis 就会启用 AOF 重写机制,来压缩 AOF 文件。
RDB 快照是如何实现的呢?
RDB 快照就是记录某一个瞬间的内存数据,记录的是实际数据,而 AOF 文件记录的是命令操作的日志,而不是实际的数据。
因此在 Redis 恢复数据时, RDB 恢复数据的效率会比 AOF 高些,因为直接将 RDB 文件读入内存就可以,不需要像 AOF 那样还需要额外执行操作命令的步骤才能恢复数据。
RDB 做快照时会阻塞线程吗?
Redis 提供了两个命令来生成 RDB 文件,分别是 save 和 bgsave:
- 执行了 save 命令,就会在主线程生成 RDB 文件,由于和执行操作命令在同一个线程,所以如果写入 RDB 文件的时间太长,会阻塞主线程;
- 执行了 bgsave 命令,会创建一个子进程来生成 RDB 文件,这样可以避免主线程的阻塞;
RDB 在执行快照的时候,数据能修改吗?
可以的,执行 bgsave 过程中,Redis 依然可以继续处理操作命令的,也就是数据是能被修改的,关键的技术就在于写时复制技术(Copy-On-Write, COW)。
为什么会有混合持久化?
RDB 优点是数据恢复速度快,但是快照的频率不好把握。频率太低,丢失的数据就会比较多,频率太高,就会影响性能。
AOF 优点是丢失数据少,但是数据恢复不快。
为了集成了两者的优点, Redis 4.0 提出了混合使用 AOF 日志和内存快照,也叫混合持久化,既保证了 Redis 重启速度,又降低数据丢失风险。
混合持久化优点:
- 混合持久化结合了 RDB 和 AOF 持久化的优点,开头为 RDB 的格式,使得 Redis 可以更快的启动,同时结合 AOF 的优点,有减低了大量数据丢失的风险。
混合持久化缺点:
- AOF 文件中添加了 RDB 格式的内容,使得 AOF 文件的可读性变得很差;
- 兼容性差,如果开启混合持久化,那么此混合持久化 AOF 文件,就不能用在 Redis 4.0 之前版本了。
Redis 如何实现服务高可用?
要想设计一个高可用的 Redis 服务,一定要从 Redis 的多服务节点来考虑,比如 Redis 的主从复制、哨兵模式、切片集群。
主从复制
主从复制是 Redis 高可用服务的最基础的保证,实现方案就是将从前的一台 Redis 服务器,同步数据到多台从 Redis 服务器上,即一主多从的模式,且主从服务器之间采用的是「读写分离」的方式。
主服务器可以进行读写操作,当发生写操作时自动将写操作同步给从服务器,而从服务器一般是只读,并接受主服务器同步过来写操作命令,然后执行这条命令。
注意,主从服务器之间的命令复制是异步进行的。
哨兵模式
在使用 Redis 主从服务的时候,会有一个问题,就是当 Redis 的主从服务器出现故障宕机时,需要手动进行恢复。
为了解决这个问题,Redis 增加了哨兵模式(Redis Sentinel),因为哨兵模式做到了可以监控主从服务器,并且提供主从节点故障转移的功能。
切片集群模式
当 Redis 缓存数据量大到一台服务器无法缓存时,就需要使用 Redis 切片集群(Redis Cluster )方案,它将数据分布在不同的服务器上,以此来降低系统对单主节点的依赖,从而提高 Redis 服务的读写性能。
Redis 主从模式中,对过期键会如何处理?
当 Redis 运行在主从模式下时,从库不会进行过期扫描,从库对过期的处理是被动的。也就是即使从库中的 key 过期了,如果有客户端访问从库时,依然可以得到 key 对应的值,像未过期的键值对一样返回。
从库的过期键处理依靠主服务器控制,主库在 key 到期时,会在 AOF 文件里增加一条 del 指令,同步到所有的从库,从库通过执行这条 del 指令来删除过期的 key。

